

这是一个Python爬虫程序,用于抓取豆瓣电影详情页面如`的数据。它首先发送GET请求,使用PyQuery解析DOM,然后根据`br`标签分割HTML内容,提取电影信息如导演、演员、类型等,并将中文键转换为英文键存储在字典中。完整代码包括请求、解析、数据处理和测试部分。当运行时,会打印出电影详情,如导演、演员列表、类型、时长等。
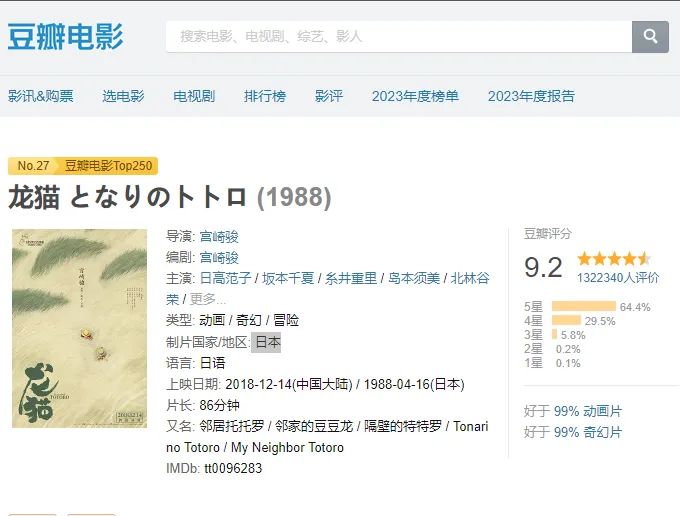
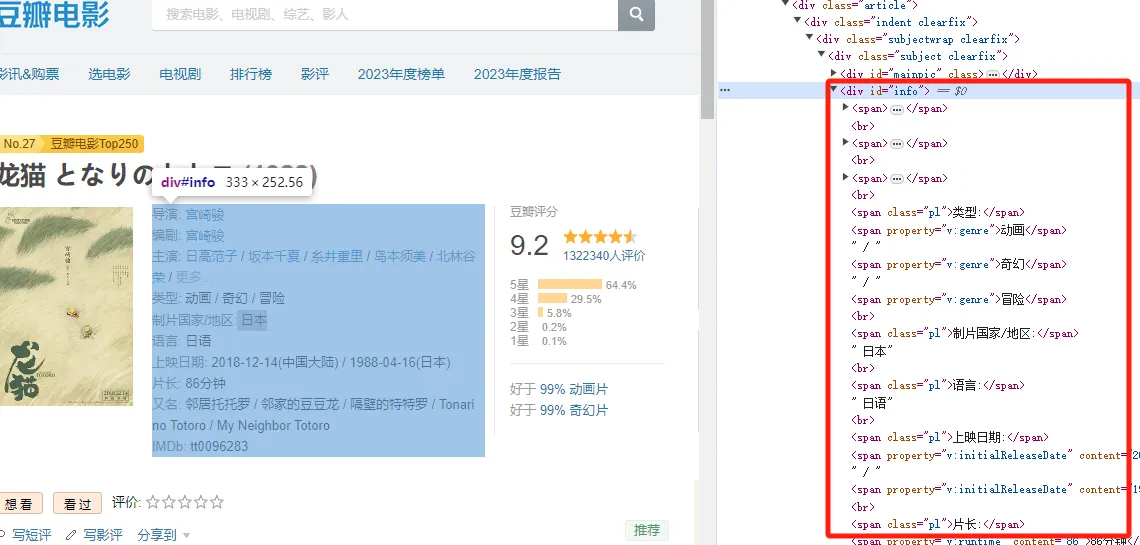
OK,经过分析,我们找到了,使用jquery 获取电影信息dom的方式,但是没什么清晰的规律。所以需要特殊处理

【优秀python案例】基于Python的豆瓣电影TOP250爬虫与可视化设计与实现
本文设计并实现了一个基于Python的豆瓣电影TOP250爬虫与可视化系统,通过获取电影评分、评论并应用词云和饼图等可视化技术,为用户提供了电影评价的直观展示和深入分析。
【优秀python web设计】基于Python flask的猫眼电影可视化系统,可视化用echart,前端Layui,数据库用MySQL,包括爬虫
本文介绍了一个基于Python Flask框架、MySQL数据库和Layui前端框架的猫眼电影数据采集分析与可视化系统,该系统通过爬虫技术采集电影数据,利用九游娱乐 九游娱乐官方数据分析库进行处理,并使用Echart进行数据的可视化展示,以提供全面、准确的电影市场分析结果。
这是一个关于如何用Python爬取2024年豆瓣电影Top250的详细教程。教程涵盖了生成分页URL列表和解析页面以获取电影信息的函数。`getAllPageUrl()` 生成前10页的链接,而`getMoiveListByUrl()` 使用PyQuery解析HTML,提取电影标题、封面、评价数和评分。代码示例展示了测试这些函数的方法,输出包括电影详情的字典列表。
使用Python和`requests`、`PyQuery`库,本文教程教你如何编写一个豆瓣电影列表页面的爬虫,抓取电影标题、导演、主演等信息。首先确保安装所需库,然后了解技术栈,包括Python、Requests、PyQuery和正则表达式。爬虫逻辑包括发送HTTP请求、解析HTML、提取数据。代码示例展示了如何实现这一过程,最后运行爬虫并将结果保存为JSON文件。注意遵守网站使用条款和应对反爬策略。
无headers爬虫 vs 带headers爬虫:Python性能对比
无headers爬虫 vs 带headers爬虫:Python性能对比
【10月更文挑战第27天】本文介绍了Python网络爬虫Scrapy框架的实战应用与技巧。首先讲解了如何创建Scra九游娱乐 九游娱乐官方py项目、定义爬虫、处理JSON响应、设置User-Agent和代理,以及存储爬取的数据。通过具体示例,帮助读者掌握Scrapy的核心功能和使用方法,提升数据采集效率。
网络爬虫是一种自动抓取互联网信息的程序,广泛应用于搜索引擎、数据采集、新闻聚合和价格监控等领域。其工作流程包括 URL 调度、HTTP 请求、页面下载、解析、数据存储及新 URL 发现。Python 因其丰富的库(如 requests、BeautifulSoup、Scrapy)和简洁语法成为爬虫开发的首选语言。然而,在使用爬虫时需注意法律与道德问题,例如遵守 robots.txt 规则、控制请求频率以及合法使用数据,以确保爬虫技术健康有序发展。
基于爬虫和机器学习的招聘数据分析与可视化系统,python django框架,前端bootstrap,机器学习有八种带有可视化大屏和后台
本文介绍了一个基于Python Django框架和Bootstrap前端技术,集成了机器学习算法和数据可视化的招聘数据分析与可视化系统,该系统通过爬虫技术获取职位信息,并使用多种机器学习模型进行薪资预测、职位匹配和趋势分析,提供了一个直观的可视化大屏和后台管理系统,以优化招聘策略并提升决策质量。
Python + Chrome 爬虫:如何抓取 AJAX 动态加载数据?